
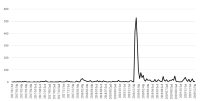
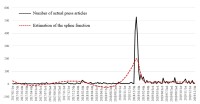
Purpose The purpose of this study is to analyze issues of sexual violence case in sports field reported in the press by using spline function model and text mining. In specific, spline function model is used to measure social interest level based on issue attention cycle theory and figure out the flow of issues by applying text mining. Methods Study material is 2,660 news articles reported from January 1, 2017 to December 31, 2019 and press DB(Big Kinds) of Korea Press Foundation is used to collect study material. Results Social interest level on sexual violence case in sports field is dramatically increased due to disclosure of Sim player starting from Me Too movement started from the culture and art world. Because of this, as structural problem in sports field arises, social interest level comes to a climax, and then it was founded that the government’s countermeasures establishment and special audits by the Ministry of Education were in progress. From the perspective of the issue attention cycle, it has the stages of latent-occurrence-rising-decision-decay-disappearance, but the period from rising to declining is short, so it corresponds to a breaking issue attention cycle. Conclusion This study examines the progress of sexual violence case in sports field from rising to disappearance in the perspective of the issue attention cycle. With this incident, the world of sports is establishing sports ethics center and proceeding policies such as Basic Sports Act, and the future studies need to review the effectiveness of this policy.

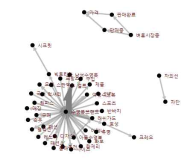
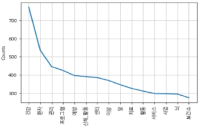
Purpose The purpose of this study was to examine the changing trends of swimsuit perception by using SNS big data. Methods By using “swimsuit” and “swimsuit brand” as key words, data was searched through blogs, cafes, Jisiksin(Tip), news, and web documents provided by naver and daum. This study used 2 years of data from January 1st, 2014 to December 31st, 2015 and social matrix program Textom was used for extracting matrix data and analyze them for frequency. To visualize data networking, NetDraw of UCINET6 program was used. Results Through analyzing the popular link words to the key words, it was known that the key words were 'swimsuit brand', 'children's swimsuit', 'rash guard', 'women's swimsuit', and 'model' in the order in 2014, and ‘swimsuit brand', 'rash guard', 'children's swimsuit', 'women's swimsuit', and 'Arena’ in the order in 2015. Second, the median of connectivity values showed that it was high in ‘swimsuit brand', 'women's swimsuit', 'children's swimsuit', 'rash guard', and 'Arena’ in the order in 2014, and ‘swimsuit brand', 'rash guard', 'women's swimsuit', 'children's swimsuit', and 'Arena’ in the order in 2015. Third, th results of CONCOR analysis demonstrated that ‘female customer’, ‘couple swimsuit’, 'rash guard', ‘brand’, 'children's swimsuit', and ‘fashion’ were grouped in 2014, and ‘brand’, ‘fashion’, 'rash guard', ‘purchase factor', and 'children's swimsuit' were grouped in 2015.





Purpose The purpose of this study is to introduce the basic concepts and procedures for topic modeling and to explain topic modeling to news articles about dementia-related physical activities. And it is also to discuss the possibility of using topic Modeling in the field of physical education. Methods In this study, the LDA algorithm of topic modeling is explained and the analysis procedure is summarized step by step by text preprocessing, text formatting, and topic number determination. The application cases were selected from 274 news articles about dementia-related physical activities reported in 13 major daily newspapers from 2000 to 2018. Results When the number of topics is 3, the Coherence Score figure is the highest. Topic 1 is about welfare services for dementia patients, Topic 2 is about prevention of dementia, and Topic 3 is about dementia research. The ratio by each subject is Topic 2 (46.0%), Topic 3 (33.2%) and Topic 1 (20.8%) in order of high ratio. Conclusion Topic modeling is an effective methodology to extract potential information excluding subjectivity of researchers. It is expected to be used when searching for information in massive texts in the field of physical education.


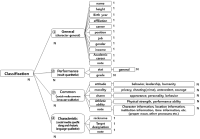
Purpose Soccer-related social media BigData includes complex information related to soccer players and is continuously and instantly generated. Text mining research is actively carried out for this kind of social media contents analysis, but it tends to be analyzed with limited linguistic characteristics such as understanding of language complexity and context, ambiguous terms, rhetoric, and new terms. This can be attributed to the fact that the tools commonly used for text mining use universal terminology dictionaries and packages that exclude the peculiarities of the analysis themes. The purpose of this study is to develop an Ontology model, which are representative tools for defining semantic ambiguity and relationships and systems between terms of text data. Methods In order to achieve the research objectives, we applied the 7-step development method of ‘Ontology Development 101: A Guide to Creating Your First Ontology’, which is useful for ontology development. Each step includes 1) Determine the domain and scope of the ontology 2) Consider reusing existing ontology 3) Enumerate important terms in the ontology 4) Define the classes and the class hierarchy 5) Define the properties of classes-slots 6) Define the facts of the slots 7) Create instances. In particular, the 3rd-step of this study, the glossary stage, is to extract core terms that make up he ontology, but since the goal of this study is to develop the ontology that can be used in social media contents analysis of soccer players, we conducted a social media text analysis related to actual soccer players and selected 484 core terms. Results The ontology which was developed in this research for social media contents analysis of soccer players consisted largely of four parts(General terms, performance results terms, common terms, and Characteristic term) and classified according to the content characteristics of the term. Conclusion Developed ontology in this study is object-oriented that defining classes and objects to define divisions and relationships between terms and also means a social media contents knowledge system of soccer players. In addition, it performs a function as a secondary tool which can be utilized for atypical data analysis.
Purpose The purpose of this study was to analyze the research topics of the articles which were published through European Sport Management Quarterly(ESMQ) from 2009 to 2018. The prior topic analysis studies of the ESMQ classified topics based on the key words using NASPE-NASSM SMPS categories. Therefore they couldn't fully reflect the content of the articles. Methods The topic modeling of the current study was conducted with the Latent Dirichlet Allocation(LDA) which generates topics based on the word usage in the article. A total of 265 articles were converted from 'pdf' format to 'txt' ANSI format for topic modeling analysis. The whole topic modeling process was done using R program and the model was set to generate 10 topics from the article. Results The 3 sport management experts were hired to label the name of the topics and the name of the topics are as follow : (1) Impact of mega sport event, (2) Cause-related marketing, (3) Factors affecting the results of the competition, (4) Managing sport organization, (5) European sport leagues, (6) Strategic management, (7) Sport economics, (8) Sport in communities, (9) Sport consumers, (10) Elite sports. It is not quite possible to compare the results of the current topic modeling results with the previous ones because of the methodological differences. However, even though the standards are different, Sport marketing topic showed the largest growth among the 10 topics extracted. Conclusions This study used the LDA probabilistic algorithm to analyze research topics, which made the analyses more objective and wholistic. However, the insights of the researchers were still needed to interpret and labeling the topics.
PURPOSE This study aimed to investigate user perceptions regarding the mobile healthcare application of public health centers by using big data. METHODS The study data included 1,089 users’ reviews (from September 27, 2016 to December 23, 2021), which were analyzed using Python, Textom, KrKwic, UCINET 6, and the Net-draw program. RESULTS First, the evaluation of the application showed a higher number of “Good” responses (677 times) compared to “Bad” (329 times) and “Normal” responses (83 times). Second, network structures related to “Good” were “Like,” “Health care,” “Help,” “A sense of purpose,” “Grateful,” “Diet management,” “Exercise management,” “Easy,” “Recommendation,” “Satisfaction,” “Diet,” “Useful,” and so on. Third, network structures related to “Bad” were “Execution error,” “Request improvement,” “Question,” “Slow speed,” “Interlocking error,” “Lack of food type,” “Login error,” “Inconvenience,” “Delete and reinstall,” “Update error,” “Irritation,” “Connection error,” “Problem occurred,” “Direct input request,” “Not available,” “Waste of stars,” “Lack of function,” “Not enough,” “Stuffy,” “Lack of exercise,” and so on. Fourth, as a result of structural equivalence analysis, four clusters appeared: cluster 1 (negative function), cluster 2 (negative emotion), cluster 3 (positive function), and cluster 4 (positive emotion). CONCLUSIONS It is necessary to respond quickly in order to reflect on the users’ reviews, and active efforts are required to improve the program quality so that users can use it conveniently.
PURPOSE This study aimed to identify the factors influencing the success of the sports entertainment program “A Clean Sweep” using big data analysis. METHODS Text mining, sentiment analysis, TF-IDF, connection centrality, and semantic network analysis were conducted using the social big data analysis program Textom and social network analysis program Ucinet6. The research period was limited from June 6, 2022 to November 30, 2023. RESULTS The factors determining success were entertainment programs, Monday, OTT, and independent league. The events and marketing factors were extracted, and A Clean Sweep X Kelly, A Clean Sweep X Mom love, cheering song, uniforms, and direct viewing day influenced success. The new hire factors were rookie draft, Young-Mook Hwang, Sung-Joon Won, and Hyun-Soo Jeong. Positive (such as good, fun, looking forward to, best, and funny) and negative (such as esoteric, regrettable, shocking, dislike, and uncomfortable) emotional factors were also extracted. The extracted star marketing factors were directors (Seung-Yup Lee, Sung-Geun Kim) and players (Dae-Ho Lee, Geun-Woo Jung, Hee-Kwan Yoo, Moon-Ho Kim, Yong-Taek Park, Taek-Geun Lee). CONCLUSIONS We were able to identify the success factors of “A Clean Sweep”, which we hope will contribute to the revitalization of professional baseball as well as sports entertainment programs.
PURPOSE The purpose of this study was to understand the current market trend for golf apparel rental services and to present basic data to revitalize the golf apparel rental service market and prepare continuous growth plans. METHODS The following keywords were selected for data collection: "golf wear + rental (렌탈)," "golf wear + rental (대여)," "golf apparel + rental (렌탈)," and "golf apparel + rental (대여).“ The analysis period was limited to two years and seven months from January 1, 2020 to July 31, 2022, when COVID-19 began. The analysis was focused on the top 60 keywords to simplify the network. RESULTS Various keywords were extracted through text mining, TF-IDF, connection centrality, emotional analysis, and semantic network analysis of big data analysis. These were then categorized into four factors: “golf apparel rental service,” “self-expression and authentication,” “sharing economy,” and “emotion.” CONCLUSIONS The results of this study show that young golfers are unreluctant and are generally positive in renting golf apparel. Therefore, if the growing paradigm of the consumption behavior of MZ-generation golfers is recognized and analyzed and the requirements are continuously satisfied through various strategies, there will be a higher possibility to help expand the golf apparel rental market.